
The Case for Holding Data Hostage
Never split the difference

I just attended the NMHC Research and Data Analytics Forum in Nashville. As I’ve written before, I’m a big fan of niche conferences focused on specific pain points; in this case, research and data. While I could write a post on nearly every talk, I couldn’t stop thinking about two conversations in particular.
The first was a question about training data for AI posed during the Q&A session of a AI and LLM presentation. Our presenter had limited time to answer, so I’m offering my thoughts here.
The second was during the networking session where we discussed the surplus of office. And yes, we talked about office in the midst of a multifamily conference. That should tell you how much of an impact office issues have on the entire real estate industry! Expect a future post on this topic. For now, let’s talk about the first point.
Training Data for AI
What happens when more and more of AI and LLM models’ training data require payment to use?
Carol asked this question after a presentation about how AI and LLMs work. Harvard has a summary that’s quite similar to the talk, which you can read here.
The success of OpenAI and others’ models presume large swaths of data. Below is the Harvard article’s timeline showing the hundreds of gigabytes required to train GPT-3.
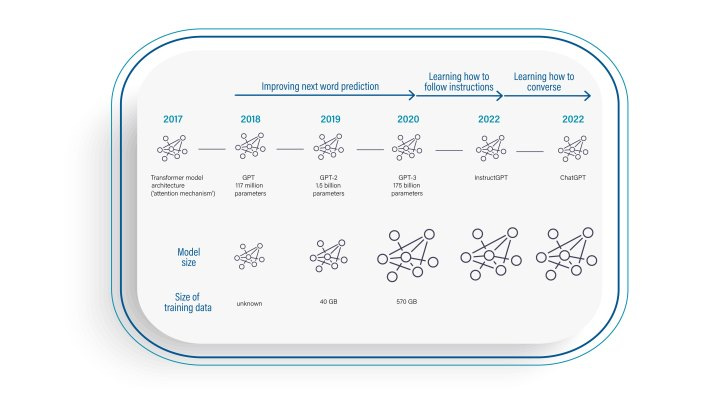
To Carol’s question, what happens when companies whose data is used by OpenAI try to hold their data hostage, demanding payment first?
We’ve already seen lawsuits hit the courtroom on this, such as the New York Times suing Microsoft and OpenAI. More recently, a federal California-based judge sided with OpenAI vs. Sarah Silverman, Michael Chabon, Ta-Nehisi Coates and other authors. The verdict likely had more to do with the argument presented. OpenAI’s results to queries are newly created works and certainly not patent infringement.
In fact, creating something new with inspiration from something old has long held up in court. Take the Ed Sheeran copyright case. He played 101 songs of the same chord to defend his music and win the lawsuit.
On the other hand, requiring payment for usage of proprietary data is also standard in many industries. Platforms, such as Reddit, hold licensing power and will begin monetizing their data.
The basic pitch is that Reddit's going to grow 20% a year, in part by licensing its users’ data to builders of large language models. Those LLMs are the very large neural networks that are trained using massive amounts of text and data, including e-books, news articles and websites like Wikipedia. That plan could work because Reddit has exactly that — lots of text.
“There's the new emerging market of AI, where large language models need data to train on,” Reddit's Chief Operating Officer Jen Wong told me on Bloomberg Technology. “And when you look at Reddit's corpus, 19 years of human experience organized by topic with moderation and relevance, that's incredibly important to building both the chat capability and the freshness of information.”
Large property management systems do this already. You may be thinking, “Jen, are you really arguing that firms should charge for their data? But by your logic, the PMSs should charge… they’re SO EXPENSIVE. How could you be in favor of that?”
My response:
Whoever does pricing for the PMSs should re-evaluate price elasticity. There is literally an army of industry experts built around getting data out of Yardi. This army uses any method other than Yardi’s prohibitively expensive APIs. I would bet good money that Yardi is leaving a LOT of revenue on the table by inaccurately presuming that demand for their data is inelastic.
Let me hop down from my soapbox and get back to Carol’s question: how will data-paywalling impact AI/LLM models in the real estate industry?
Certain models will be better at specific tasks because they have access to niche, higher quality training data.
The firms who amassed said data will have the capacity to profit if they’re smart about it.
If regulation burdens development due to concerns over propriety, AI models may be slower to advance. But they will advance.
Let’s walk through each of these together.
1. Certain models will be better at specific tasks because they have access to niche, higher quality training data.
If you’re Greystar, you have tons and tons of data at your fingertips across hundreds of thousands of units. If you capture and own your data, you could use it in a GPT model and gain a huge advantage over your competitors. Similarly, tech vendors with loads of aggregated data could automate or improve tasks.
For example, chatbots used to converse with prospective residents will be better at predicting responses via more chatbot data. Platforms that have access to tons of commercial leases will be better at writing new ones based on detailed prompts. They’ll have more knowledge of special situations.
In a later talk at the conference, Shawn Mahoney from RETV spoke about the need for AI to generate business intelligence. He argued that many noobs to BI and data analytics will misinterpret data. Or worse, in my experience, they will massage the data to get the answer they want rather than approaching data analysis as a science experiment with a hypothesis. This is not yet possible, but it’s coming. You will need a ton of accurate, high quality data to train the AI model for this type of solution.
As I predict in a previous post, The Data Death Star:
Better infrastructure and increased data governance meant higher data quality [in the late 2020s and early 2030s]. By having confidence in their data, commercial real estate firms started to use AI and LLMs to automate more and more tasks.
Conversely, if firms start holding their data hostage and demanding payment before usage, then the models will get worse. You’re essentially wiping the memory of those data points.
Think Eternal Sunshine of the Spotless Mind.

The way that OpenAI works, for example, is to retrain each new model on a complete and massive dataset. We have a conundrum where now, more and more data is generated by AI. Training the trainer will result in less authentic results. E.g., an average of averages is less precise than an average taken from the raw data.
This will naturally create more optionality and industry-specific AI/LLM models. Companies who offer these models will eventually be resource constrained and focus on niches. They will pay for the data that will garner them the majority of a specific market, and grow vertically as a result.
The most powerful data companies will be those that capture authentic, human contributions within each market.
2. The firms who amassed said data will have the capacity to profit if they’re smart about it.
Not all training data is created equal. Let’s go back to the Reddit article from Bloomberg.
Reddit's argument is that its data is more valuable than others’ because, ironically, it reflects actual human input at different layers. The posters are human, a post's spot in a forum's timeline is voted on by humans and the volunteers that moderate the content and uphold content policies are also — human. That's particularly valuable in a world where more and more AI-generated content is shared on social media platforms, argues Wong.
Tech firms in particular have a massive opportunity to profit, similar to Reddit. I expect to see CRE and multifamily tech firms focus on data monetization in the near future. Large real estate firms may also be among the first to profit from their data. I wrote about this in The Data Death Star article referenced above. Then, smaller real estate firms will have the opportunity to make money on their valuable info, often in markets or types not covered by the big guys.
The “smart about it” part refers to both licensing and protecting your data while also identifying the ways in which others will purchase your data. Any AI/LLM product is only as good as the data you give it, and the real estate industry is an industry of niches.
What do I really mean by niche within a niche, etc.? Well, let’s say you’re evaluating a startup that says they serve senior living, but really, their product is only applicable to assisted living. Starting from the top: Multifamily → Senior Living → Assisted Living. That’s a niche within a niche.
In any new market, you have to work to find customers. Think of this as finding product-market fit.
Firms that want to sell their data within the commercial real estate sector will work harder to find that enviable product-market fit.
3. If regulation burdens development due to concerns over propriety, AI models may be slower to advance. But they will advance.
Marc Andreesen responded to this post by Maxwell Tabarrok. Andreesen argued that requesting information from AI is essentially the same as requesting information from a search engine.
Search and AI/LLMs today have some similarities in deployment. For example, libraries exist to bring their functionality to private, local environments. The main difference between search and AI/LLMs imo is that we have a tendency to think GPT models can do more than they can. They are limited in just the same way as search by your local data environment and industry niche.
When Google became big, regulators weren’t quick to regulate. Instead, they were struck by the shiny object syndrome of the new-new thing that was so cool. We now have search functionality across all applications. Will we say the same of AI/LLMs if regulators get involved?
Probably not. At least, not as quickly.
Yes, I’m all about safeguards for children. Yes, requests for information on self-harm should be presented with information on self-help and support. At the same time, we’re kidding ourselves if we think that somewhere in the world, some entity won’t take this technology to the next level.
Sunny Juneja will present the argument in favor of AI advancement tomorrow at the House Financial Services Committee.
Let’s hope we win the fight for technology progress.
Jen’s Startup of the Week
None this week.
Jen’s Reading Corner
If and when you start to negotiate data contracts—or frankly, any contract—you should read Never Split The Difference by Chris Voss.

If you like All About CRE and want to support my work:
😍 Plan a media partnership
🪄 Book a one-on-one CRE tech coaching session
☕ Buy me a coffee
📧 Forward this to a friend and invite them to subscribe at jentindle.substack.com